The main goal of the following cookbook is to ensure that a speech corpus is usable in the sense that a prospective user may exploit the data of the corpus for his/her purposes without having to fight with technical problems. Most of these problems arise from one of the following basic `flaws' of the corpus:
The aim of the following step-by-step instructions is to detect such `flaws' in a corpus. The validation procedure results in a validation report. This validation report summarizes the findings, both positive and negative with respect to the specifications. For the producer it is a proof that the work has been done properly, for the client it is an (independent) judgment on the technical quality of the corpus.
Since we cannot forsee all possible errors in all possible speech corpora once and for all time, the motivation of the user of this cookbook should be to find all errors that might hinder the successful usage of the speech corpus. Therefore we do not recommend following the instructions to the letter but rather seeing them as analogies that have to be adapted for the special needs of the actual corpus at hand.
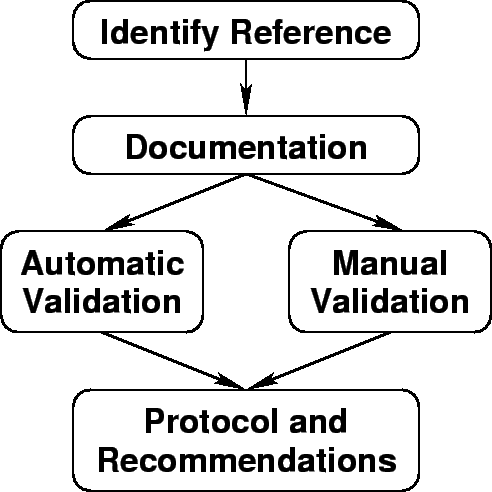
The remaining document is organized as follows (see fig. 2.1):
The first Chapter 3 `Reference and Check List' describes how to define the reference against which the validation has to be performed. Since you cannot validate without such a reference, this has to be done first. We give hints on how to define the list of check items and how to set up a `validation contract' with the producer / client.
Chapter 4 `Documentation' provides some help on how to tackle the problem of possible flaws in the documentation of the corpus. Since this is neither a problem of man power nor programming skills, we will simply give you some hints on how to `see' the documentation with the eyes of a prospective user. This part is traditionally the hardest to perform in in-house validations because it requires `forgetting' everything that has been done during the production of the corpus.
Chapter 5 `Automatic Validation' covers all checks that might be performed automatically on the complete corpus. Since these checks require only programming skills and machine power, they can typically performed by one person or a very small group.
Chapter 6 `Manual Validation' deals with checks that cannot be performed automatically and will therefore most likely be applied only to a selected subset of the corpus. This chapter gives some hints about the selection techniques and describes some basic techniques for manual checking. Typically you will reserve more man power for this part of the process.
The tasks described in chapter 5 and 6 can be carried out in parallel.
Finally, in chapter 7 `Validation Report' we gives a rough structure of what should be contained in the final report.
Note that the result of a validation is not necessarily a perfect corpus. However, a speech corpus with well documented deviations from the specifications is more valuable than a corpus without a validation.