EMU-SDMS tutorial
This tutorial is meant as a quick introduction to the EMU-SDMS. A lot of the topics described in this tutorial will be explained in depth throughout this course.
Initially please make sure the course_data_dir and course_data_url variables are set
course_data_dir = "./myEMURdata" # change to valid dir path on your system
course_data_url = "http://www.phonetik.uni-muenchen.de/~jmh/lehre/Rdf"How to create a speech database semiautomatically?
The main goal of this section is to get an idea of how an EMU-SDMS speech database is structured. We will process a so called emuDB semiautomatically, by sending audio recordings that contain speech and corresponding orthographic transcriptions of the text to a web-based service that carries out a grapheme-to-phoneme conversion; after that, a process called forced-alignment aligns the phonemic classes (=symbols) with the respective acoustic signals, i.e. segments the audio signal into a given number of segments, and labels these segments with the corresponding phonetic symbols.
The automatic segmentation and labeling of speech signals will be done using the BAS (‘Bavarian Archive for Speech Signals’ tools. These services can be invoked from R using the emuR-package.
1.1 Packages
Many functions that we will need in this seminar are not available in base R, especially none for working with speech databases. However, many more specialized functions have been made available by developers of so-called packages or libraries. To make these functions available to us, we need to install the corresponding packages.
In RStudio:
Tools–>Install Packages
or install.packages("packagename") in the R console; we will need “emuR” for speech database creation and analysis, “dplyr” for the manipulation of data, and “ggplot2” for plotting data which are included in the tidyverse package:
install.packages("emuR")
install.packages("tidyverse") # we will mainly use dplyr & ggplot2 in this courseAfter the installation process (which might take a while), you still have to attach the functions to R’s search path:
# load package
library(emuR)We have now loaded the package emuR, and its functions are now available.
You should update packages in regular intervals. The easiest way to do so: Tools–>Check for Package Updates…
1.2 First step - make sure to have valid transcriptions of your speech recordings!
Unless you are going to use automatic speech recognition (which is possible in the BASwebservices), you will need transcriptions of the utterances spoken in your audio recordings. In all cases, both the audio and the text file must have the same basename.
We will start here with a collection of audio files in the format ‘wav’ which are accompanied by text files in the format ‘txt’. Please download such a collection from ‘testsample.zip’ to your personal folder, whose path is saved in object course_data_dir that should be in your R workspace, e.g.:
course_data_dir## [1] "./myEMURdata"Go to this path, unzip ‘testsample.zip’, and then open the subfolder ‘testsample/german’!
You will see four files, i.e. two pairs sharing the same basename, and one file each with ‘.wav’ and ‘.txt’ extension:
list.files(file.path(course_data_dir, "testsample/german"))## [1] "K01BE001.txt" "K01BE001.wav" "K01BE002.txt" "K01BE002.wav"Listen to the wav-files, and open the txt-files. Make sure, that audio and transcription are congruent!
K01BE001.txt contains the words “heute ist schönes Frühlingswetter”, and K01BE002.txt “die Sonne lacht”.
Btw., you could also use texts that contain punctuation marks, or capital letters at the beginning of a sentence. The BASWebservices will automatically remove things like that by so-called ‘text normalization’ (e.g. “Heute ist schönes Frühlingswetter!” –> “heute ist schönes Frühlingswetter”). Text normalization usually also translates special symbols and strings into its written word form, e.g. “%” will become “Prozent” (or “percent”, depending on the language you have chosen); this sometimes fails, so, in order to be sure, you might think of replacing such things by yourself (e.g. “1990” will be translated into “eintausendneunhundertneunzig” (the number), not into “neunzehnhundertneunzig” (the year)).
1.3 Use convert_txtCollection() to create a simple emuR speech database
The library emuR contains a function that creates computer-readable connections between audio and text. The function to do so is convert_txtCollection(). It converts a collection of paired audio (in wav-format) and text (in txt-format) -files into a very simple speech database on the assumption, that .wav and .txt -files of the same basename are connected with each other. The pairs must have the same basename: otherwise, the function will fail.
You need to define the path to the audio-text-collection (the sourceDir), the path to the database (the targetDir), and, of course, the name of the database. First of all, let’s define the sourceDir (which we will call ‘pathger’) and the targetDir (which we will call ‘targetger’):
pathger = file.path(course_data_dir, "testsample/german")
targetger = course_data_dirThen use convert_txtCollection() to create the database:
convert_txtCollection(dbName = "gertest",
sourceDir = pathger,
targetDir = targetger)Congratulation, you have created you first EMU-SDMS speech database (usually simply referred to as an emuDB)! It is extremely simple, as it only connects the written text to the speech signal, but this connection is machine-readable.
Now go to “course_data_dir” in your file browser and have a look at its contents. First of all, you will notice a subfolder called ‘gertest_emuDB’. This subfolder contains another subfolder, called ‘0000_ses’, and a file called ‘gertest_DBconfig.json’. This file contains text that defines the speech database and that can be viewed in any text editor:
{
"name": "gertest",
"UUID": "bb3d8920-317e-450f-a64c-ba46b714fd0d",
"mediafileExtension": "wav",
"ssffTrackDefinitions": [],
"levelDefinitions": [
{
"name": "bundle",
"type": "ITEM",
"attributeDefinitions": [
{
"name": "bundle",
"type": "STRING"
},
{
"name": "transcription",
"type": "STRING",
"description": "Transcription imported from txt collection"
}
]
}
],
"linkDefinitions": [],
"EMU-webAppConfig": {
"perspectives": [
{
"name": "default",
"signalCanvases": {
"order": ["OSCI", "SPEC"],
"assign": [],
"contourLims": []
},
"levelCanvases": {
"order": []
},
"twoDimCanvases": {
"order": []
}
}
],
"activeButtons": {
"saveBundle": true,
"showHierarchy": true
}
}
}
More important for us are the contents of the folder ‘0000_ses’. It contains two subfolders, one each for each recording. The subfolders’ names are built up by the aforementioned paired basenames (‘K01BE001’ and ‘K01BE002’, respectively), followed by ’_bndl’ (which can be read as ‘bundle’, because it bundles all files that have a connection to a certain recording in one folder). So far, each bundle consists of only two files, i.e. a copy of the wav-file, and an annotation file called ’basename_annot.json’. In the case of the first utterance’s ‘K01BE001_annot.json’ file, it now looks like this:
{
"name": "K01BE001",
"annotates": "K01BE001.wav",
"sampleRate": 16000,
"levels": [
{
"name": "bundle",
"type": "ITEM",
"items": [
{
"id": 1,
"labels": [
{
"name": "bundle",
"value": ""
},
{
"name": "transcription",
"value": "heute ist schönes Frühlingswetter"
}
]
}
]
}
],
"links": []
}1.3.1 load_emuDB()
The simple audio-text-collection has so far been converted to a structure containing subfolders and transformations from simple text in txt-format to a so-called ‘.json’ format that is readable in R.
For this purpose, close all editors you might have opened (be sure not to save anything), and go back to RStudio and enter:
db_ger = load_emuDB(file.path(targetger, "gertest_emuDB"))summary(db_ger)## Name: gertest
## UUID: 3f63ab8a-11b1-48a3-ad81-ab59c9e0ee4a
## Directory: /Users/reubold/myEMURdata/gerDB/gertest_emuDB
## Session count: 1
## Bundle count: 2
## Annotation item count: 2
## Label count: 4
## Link count: 0
##
## Database configuration:
##
## SSFF track definitions:
## NULL
## level definitions:
## name type nrOfAttrDefs attrDefNames
## 1 bundle ITEM 2 bundle; transcription;
##
## Link definitions:
## NULLThis summary gives us some some general information about our database, e.g. that it is saved in a certain Directory (in this case “./myEMURdata/gerDB/gertest_emuDB”), that it consists of two bundles, and we can guess that there is some sort of transcription going by the Label count of 4.
1.3.2 serve(): the EMU-webApp
We can now listen to the recordings of the database and also visualise the audio. To do so, we use the function serve(databaseName). By entering this command into R, and the data will be shown in the so-called ‘EMU-webApp’ within RStudio (as of emuR Version 2.0.3). Audio data is presented visually as waveform and spectrogram, and it can be played back (e.g. by clicking on ‘play in view’).
serve(db_ger)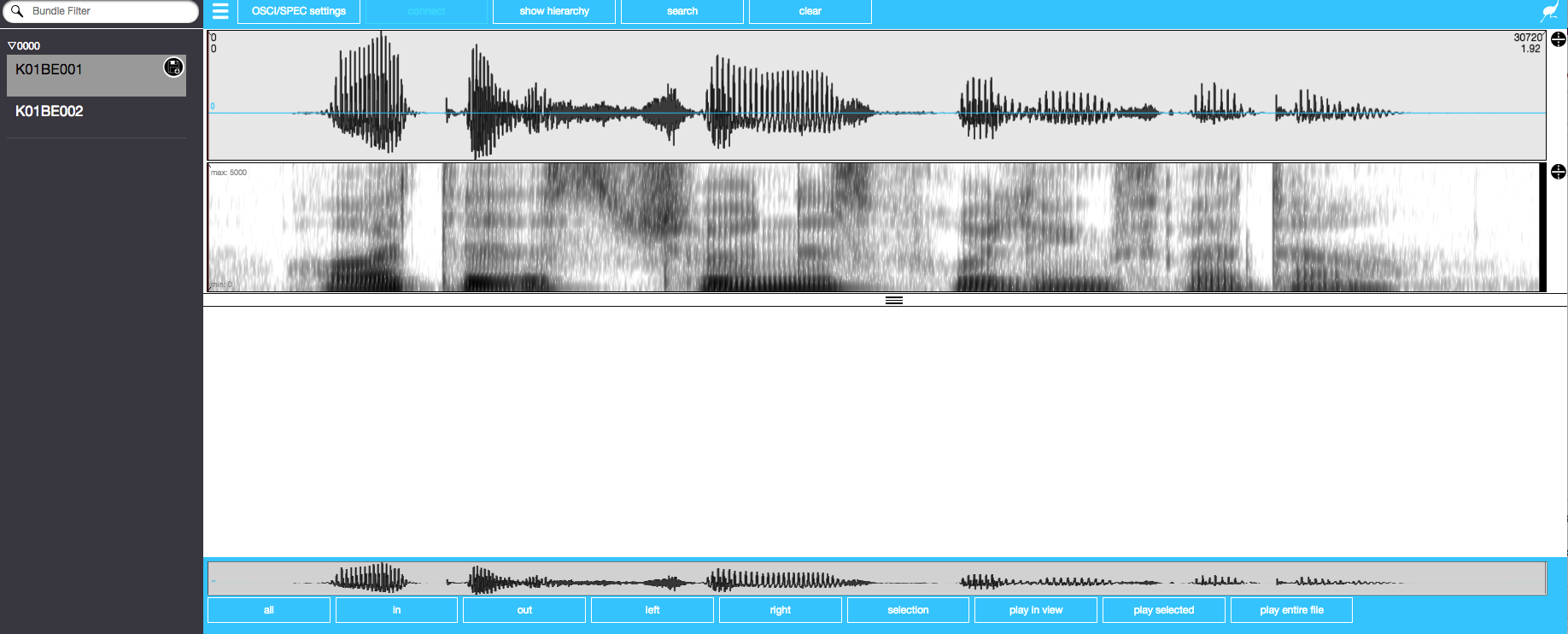
The EMU-webApp showing waveform and spectrogram of the first utterance K01BE001
1.4 runBASwebservice_all()
The task now is to carry out forced alignment i.e. to provide a phonemic segmentation given the orthography and speech signal.
Please close your webbrowser (and therefore the EMU-webApp) and run the following function in R (this may take a while):
runBASwebservice_all(db_ger,
transcriptionAttributeDefinitionName = "transcription",
language = "deu-DE")If we now look at the data in the EMU-webApp, we will see segments:
serve(db_ger)
# or, depending on your browser / browser version:
serve(db_ger,autoOpenURL = "https://ips-lmu.github.io/EMU-webApp/?autoConnect=true")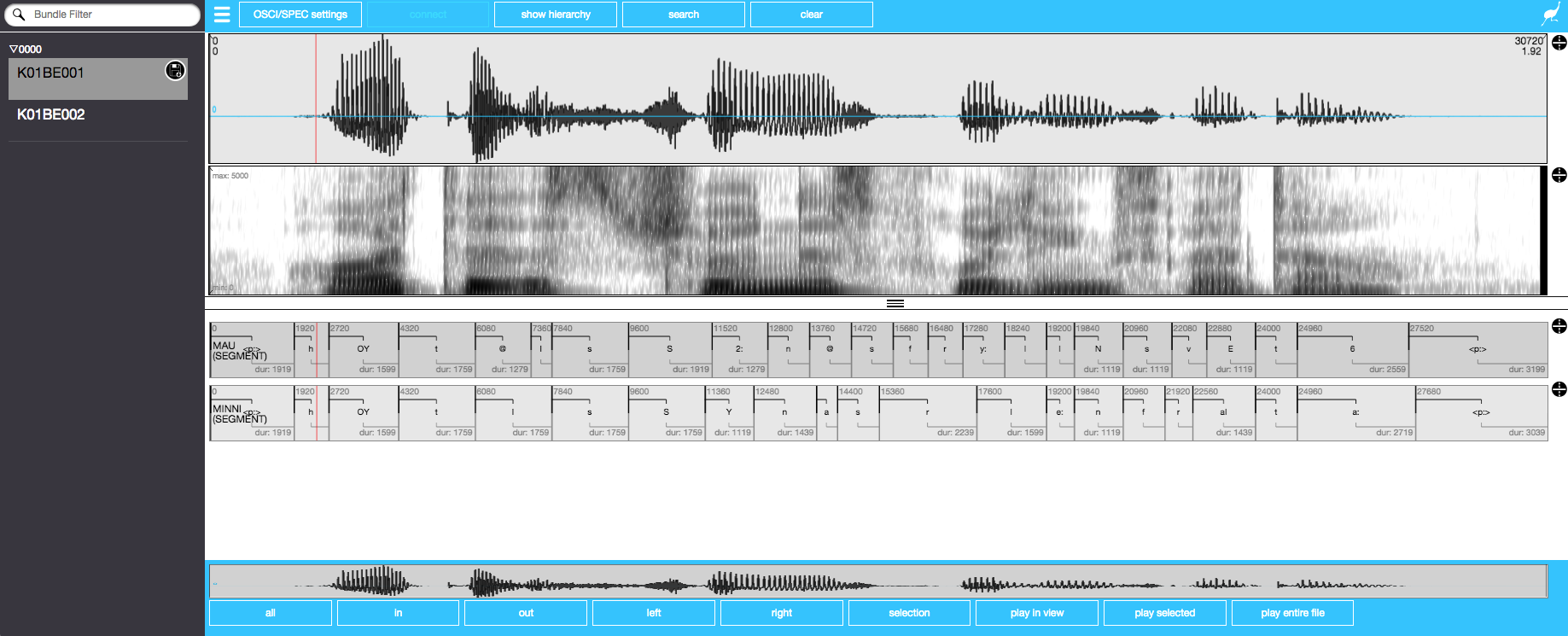
The EMU-webApp showing waveform, spectrogram, MAU segments, and MINNI segments of the first utterance K01BE001 after segmentation by the BASwebServices
Some further details on creating the phonemic transcriptions are as follows.
Starting from an orthographic transcription,
runBASwebservice_all()derives a tokenized orthographical word level using the so-called G2P (‘grapheme-to-phoneme’) tool, which creates the canonical phonemic transcription (in SAMPA) based on the input txt and a trained statistical model based on a language specific lexicon.Subsequently, the webservice MAuS (Munich Automatic Segmentation) is called to derive a phonetic segmentation via so-called forced-alignment. The canonical phonemic transcription created by G2P is transformed into the most probable phonetic form, again based on trained statistical models of all possible phonetic forms and on the best fit to the acoustical signal. This most probable phonetic form - a string of phonetic symbols - is aligned to the signal, i.e. start and end times of segments are calculated, again based on statistical speech models. The resulting segment boundaries (defined by the start and end times) and labels are written into MAU (= the first level of segments that you can see in the EMU-webApp).
runBASwebservice_all()also creates a second, rough segmentation by running the phoneme decoder MINNI. Based on statistical models about speech signals of the given language, MINNI works without any txt-input, but is instead based solely on the acoustical signal.Finally, syllabification is performed by calling the service Pho2Syl.
It has been mentioned that with the exception of MINNI all steps in
runBASwebservice_all()require a transcription. The user defines this transcription bytranscriptionAttributeDefinitionName = "transcription"It has also been mentioned, that many of the steps of
runBASwebservice_all()are dependent on language-specific statistical models; therefore, users have to define the language withlanguage = "LANGUAGE"(Up-to-date lists of the languages accepted by all webservices can be found here). E.g.language = "deu-DE"defines German (spoken by L1-German speakers raised in Germany).For other processing options to convert
txtCollectionstoemuDBs see: https://clarin.phonetik.uni-muenchen.de/BASWebServices/interface/Pipeline
2 The annotation structure in Emu
The annotation structure for any utterance in the EMU system is organised into one or more levels (or tiers). Each level consists of a number of annotations. There are three types of levels.
2.1 The three types of levels
Firstly, there are segment levels whose annotations are known as SEGMENTs. MINNI and MAU are segment levels because each annotation has a start time and a duration.
Secondly, there are event levels containing so-called EVENTs that are defined by a single point in time. Event levels are commonly used in tones-and-break-indices (TOBI) transcriptions in order to define the time at which tone targets occur.
Thirdly, there are item levels that inherit their times via links from (in almost all cases) segment levels. The annotations at these levels are called ITEMs.
For this example, the command runBASwebservice_all() created two item levels ORT and MAS whose items are the words and their syllabifications respectively. (The syllabification is based on something known as the maximum onset principle according to which as many consonants as possible are syllabified with a following vowel, as long as the sequence of consonants forms a phonotactically legal cluster in the language).
The two different types of levels for the database created so far can be seen in the second column of:
list_levelDefinitions(db_ger)## name type nrOfAttrDefs attrDefNames
## 1 bundle ITEM 2 bundle; transcription;
## 2 ORT ITEM 3 ORT; KAN; KAS;
## 3 MAU SEGMENT 1 MAU;
## 4 MINNI SEGMENT 1 MINNI;
## 5 MAS ITEM 1 MAS;2.2 Attributes
It is possible to assign more than one label to each annotation item (i.e. to each SEGMENT, EVENT, or ITEM). These different labels are called ATTRIBUTES. E.g., the list of level definitions shows for level 2 ‘ORT’ 3 attribute definitions, ORT (the orthographic form, e.g. “Sonne”), KAN (the canonical phonemic form, e.g. /zOn@/), and KAS (same as KAN, but with syllabification: /zOn.@/).
The item levels and their association to the MAU segment level can be viewed as follows. Re-open the EMU-webApp:
serve(db_ger)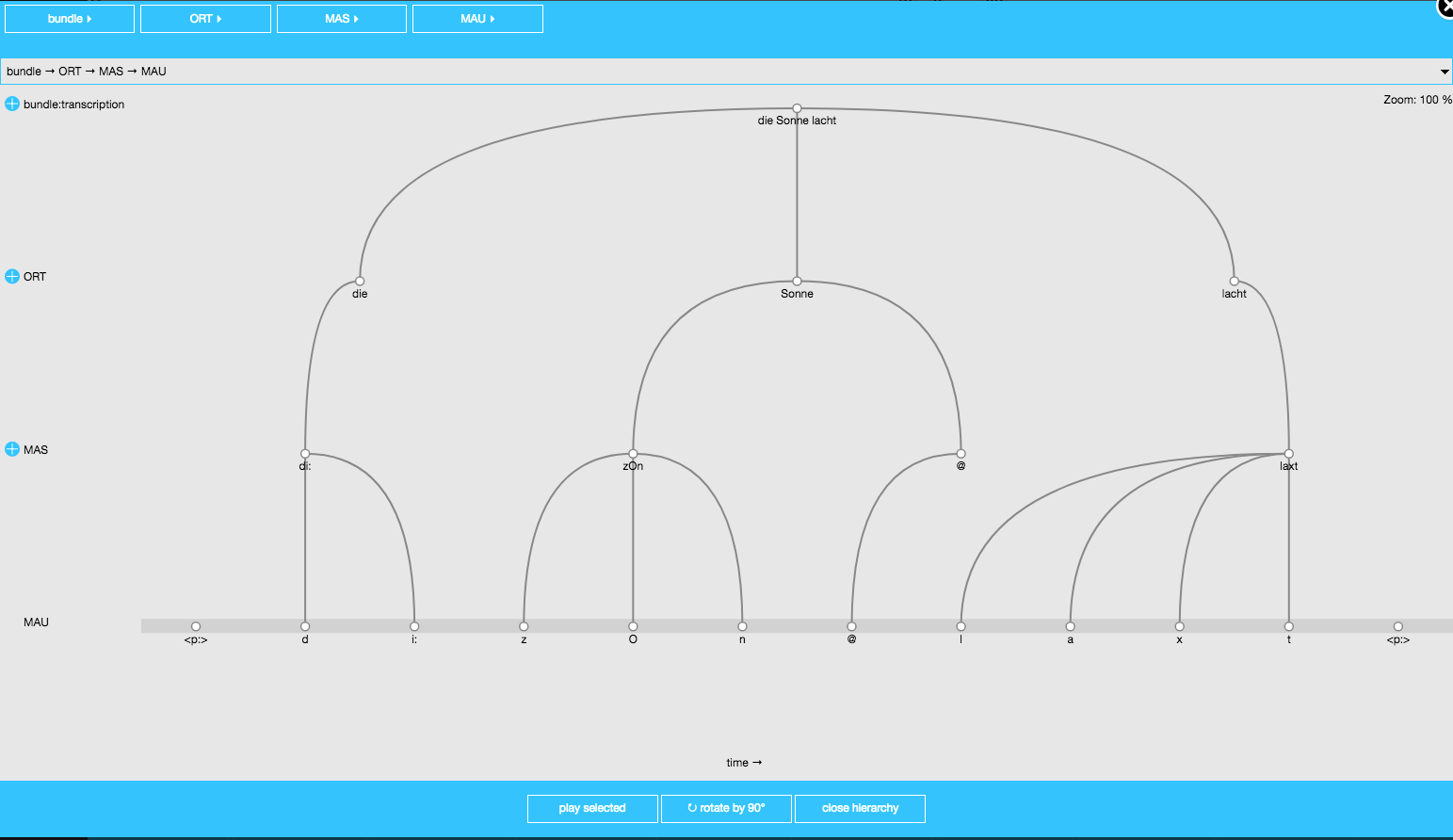
Hierarchical structure of the utterance “Die Sonne lacht” (in the EMU-webApp)
Choose the second utterance (or bundle) and click on show hierarchy; you can choose from the drop-down menu for each level in the upper part of the browser window to select which label or attribute is to be displayed. You can also click on ‘rotate by 90°’.
2.3 The hierarchy and time information
Start and end times of an item level are inherited from segment levels. Thus the start time of the annotation “Sonne” of the item level MAU is the same as the start time of [z] of the segment level MAU. The end time of “Sonne” is the same as the end time of the segment [@]. For the same reason, the annotations “Sonne” of the ORT level, [zOn] of the MAS level, and [z] of the MAU level all have the same start time. In this way, the durations of any annotations of the ORT or MAS levels are known because of the links to the segment level MAU.