A (very) short introduction to the EMU-SDMS
In this course we want to work with speech databases in R. Several questions arise:
- What do we consider to be a speech database?
- What types of data do we want to analyse?
- How will we annotate our data?
- What types of signal processing will we need? (Formants anyone?)
- What types of annotation structures would we like to use?
- …
And then finally: Is it possible to analyse speech databases in R without using something like the EMU-SDMS? The answer to this final question is a definite yes (especially if you include the use of external tools such as Praat or ELAN). However (huge HOWEVER!), it can be very VERY difficult and cumbersome to do as well as being quite error prone, as you would basically have to write a lot of the functionality provided by the EMU system. As an example: could you write a script that extracts the following: formant trajectories of all “W” (weak) syllables in word-final position occurring in three-syllable words out of a multi-tiered collection of TextGrids? If you can answer the question with: nothing easier than that - then the EMU-SDMS probably won’t be super beneficial to you (although it does offer other benefits which we will get into later in the course). If that is not the case, then this course will show you how this can be achieved using the emuR package.
The EMU Speech Database Management System (SDMS)
System Architecture
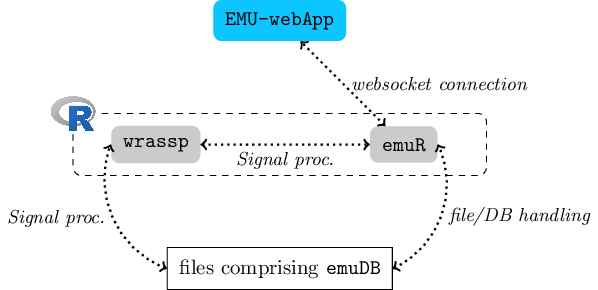
Schematic architecture of the EMU-SDMS
Default Workflow
- Load database into current R session (
load_emuDB()). - Database annotation / visual inspection (
serve()). This opens up theEMU-webAppin the system’s default browser. - Query database (
query()). This is optionally followed byrequery_hier()orrequery_seq()as necessary (see Chapter @ref(chap:querysys) for details). - Get trackdata (e.g. formant values) for the result of a query (
get_trackdata()). - Prepare data.
- Visually inspect data.
- Carry out further analysis and statistical processing.
Installation
The only component that has to be installed is the emuR package. As with all R packages this can be done as follows.
install.packages("emuR")The current version of emuR is 2.0.3
Further Reading
https://ips-lmu.github.io/The-EMU-SDMS-Manual/chap-overview.html