Querying an EMU-SDMS database
Initially please make sure the course_data_dir and course_data_url variables are set:
course_data_dir = "./myEMURdata" # change to valid dir path on your system
course_data_url = "http://www.phonetik.uni-muenchen.de/~jmh/lehre/Rdf"We will use a demo emuDB in this lecture that comes with the emuR package; we will ‘create’ this database by using the function create_emuRdemoData; the data base will be saved at course_data_dir:
# load packages
library(emuR)
library(tidyverse)# create demo data in directory
create_emuRdemoData(dir = course_data_dir)
# create path to demo database
path2ae = file.path(course_data_dir, "emuR_demoData", "ae_emuDB")
# load database
ae = load_emuDB(path2ae, verbose = F)
# get summary of loaded emuDB
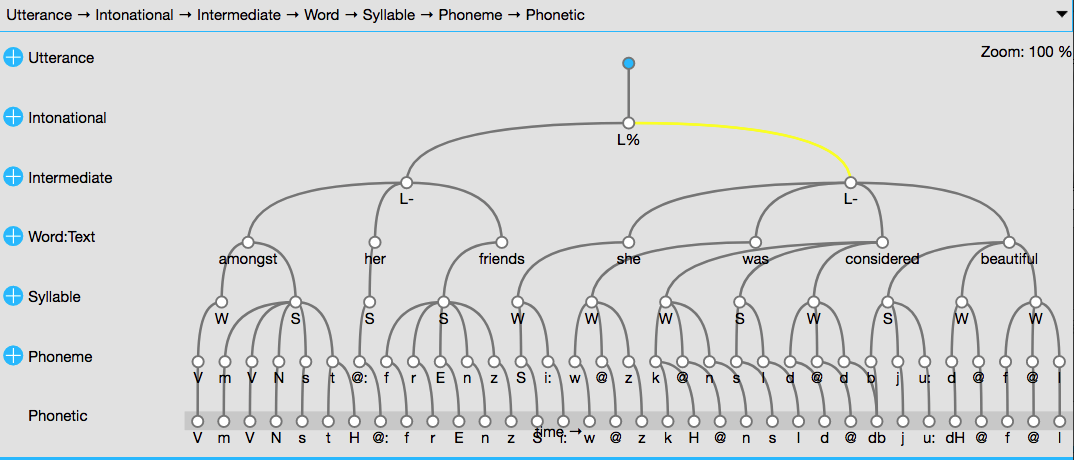
summary(ae)In the level definitions, we see one EVENT level (“Tone”, one point in time), one SEGMENT level (“Phonetic”, with start and end times), and several ITEM levels, e.g. “Syllabe” or “Word”, which inherit time information from the level “Phonetic”. In the link definitions summary section, we can see a very rich annotation structure, which results in the following tree-like structure for the first utterance (note that only a single path through the hierarchy is shown):
serve(ae)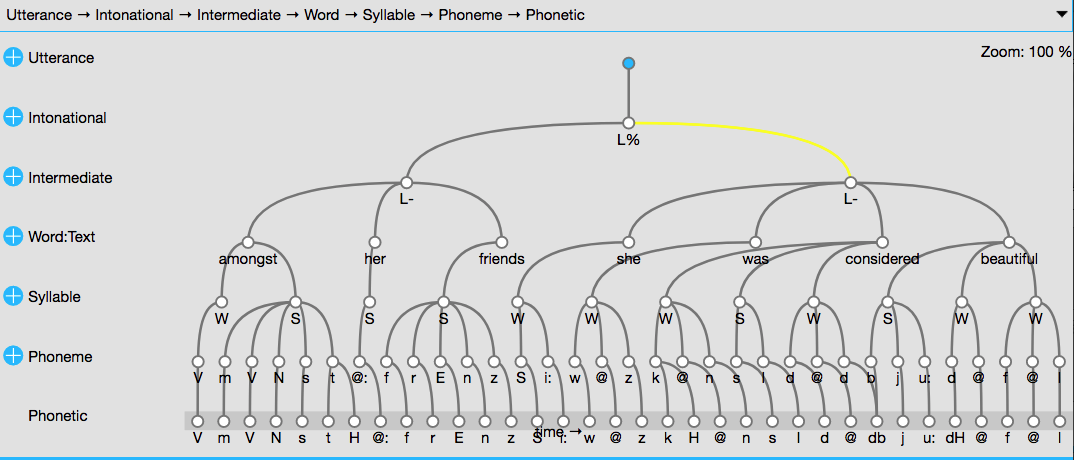
Figure 1: Hierarchy of the first utterance of the database ae
We can also see so-called SSFF track definitions, which means in this case that - amongst other things - pre-calculated formants are available.
It is worth noting that all seven utterances were read by the same speaker, so there will be no concerns about things like vowel normalisation. The male is a speaker of Australian English (therefore the database’s name ae).
Example of an analysis
We will now present a little example of how such a database could be analysed. To do so, we will use the function query() to query certain segments, get_trackdata() and other functions to read formants into R, and requery_hier() for further re-analysis.
First of all, we want to plot the edges of the Australian English vowel space. To do so, we will query back and front closed, mid, and open vowels.
# query A and V(front and back open vowels),
# i: and u: (front and back closed vowels), and
# E and o: (front and back mid vowels)
ae_vowels = query(emuDBhandle = ae,
query = "[Phonetic== V|A|i:|u:|o:|E]")
# get the formants that belong to the queried segments:
ae_formants = get_trackdata(ae,
seglist = ae_vowels,
ssffTrackName = "fm")
# get the formants at the vowels' temporal midpoints:
ae_formants_norm = normalize_length(ae_formants)## Warning: Row indexes must be between 0 and the number of rows (14). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (17). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (16). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (9). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (15). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (13). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (18). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.## Warning: Row indexes must be between 0 and the number of rows (19). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.ae_midpoints = ae_formants_norm %>%
filter(times_norm==0.5)
# plot the vowel space:
ggplot(ae_midpoints) +
aes(x = T2, y = T1, label = labels, col = labels) +
geom_text() +
scale_y_reverse() + scale_x_reverse() +
labs(x = "F2 (Hz)", y = "F1 (Hz)") +
theme(legend.position = "none")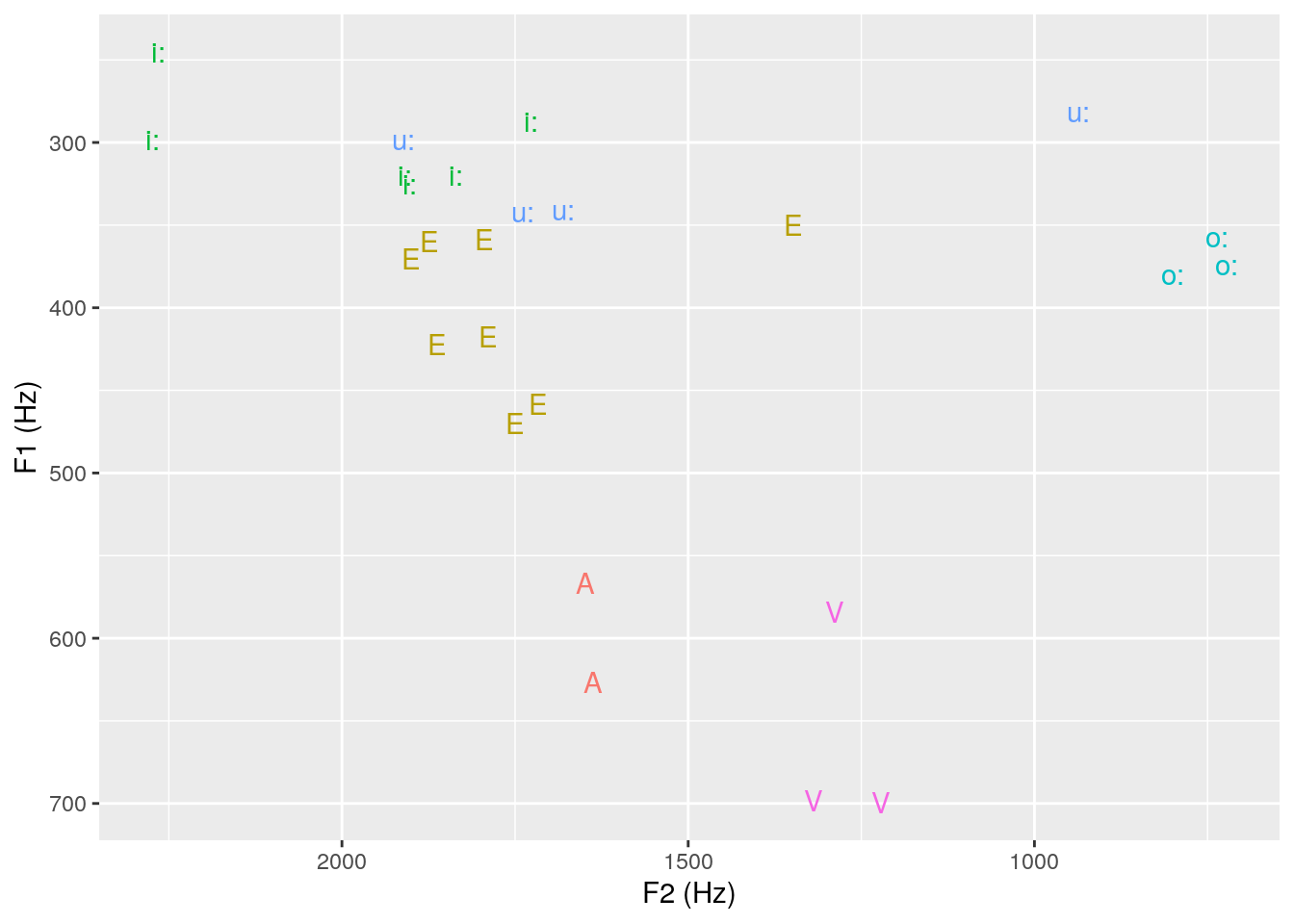
This figure shows a vowel space as one would expect it: open vowels are near the bottom, closed vowels are on the top, mid vowels in the mid. Front vowels are on the left side of the plot, and back vowels are on the right-hand side. However, there is an exception: only one out of four /u:/s is actually really back, the other three are extremely fronted.
In order to re-inspect the data, we will now concentrate on /u:/:
ggplot(ae_midpoints %>%
filter(labels == "u:")) +
aes(x = T2, y = T1, label = labels, col = labels) +
geom_text() +
scale_y_reverse() + scale_x_reverse() +
labs(x = "F2 (Hz)", y = "F1 (Hz)") +
theme(legend.position = "none")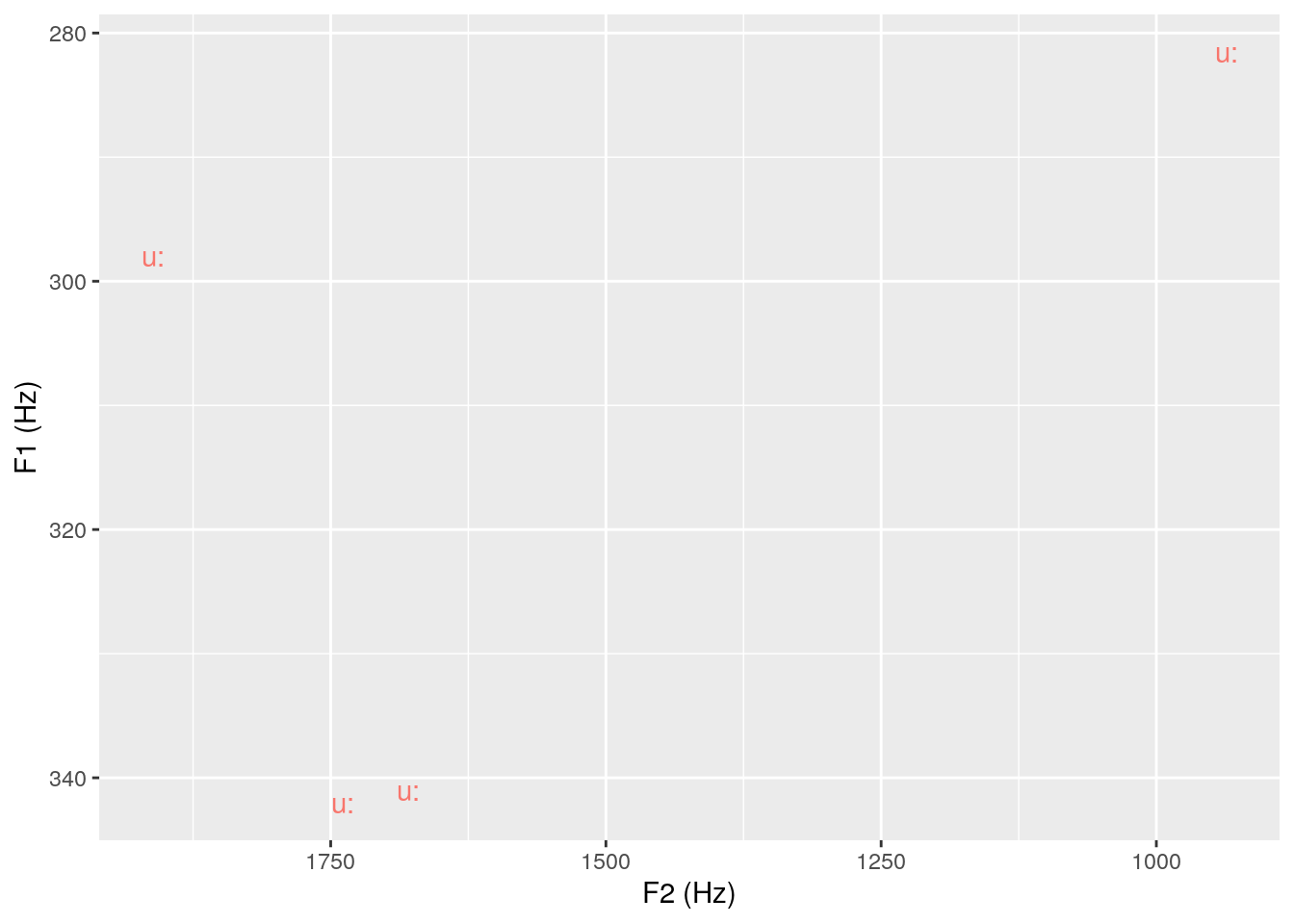
In order to find out why three out of four /u:/ are so front, we should find out the words; this can be done by examining to which words the four /u:/s were linked (by means of requery_hier()):
ae_midpoints$Word = requery_hier(ae,
seglist = ae_vowels,
level = "Text")$labels
ggplot(ae_midpoints %>% filter(labels == "u:")) +
aes(x = T2, y = T1, label = Word, col = labels) +
geom_text() +
scale_y_reverse() + scale_x_reverse() +
labs(x = "F2 (Hz)", y = "F1 (Hz)") +
theme(legend.position="none")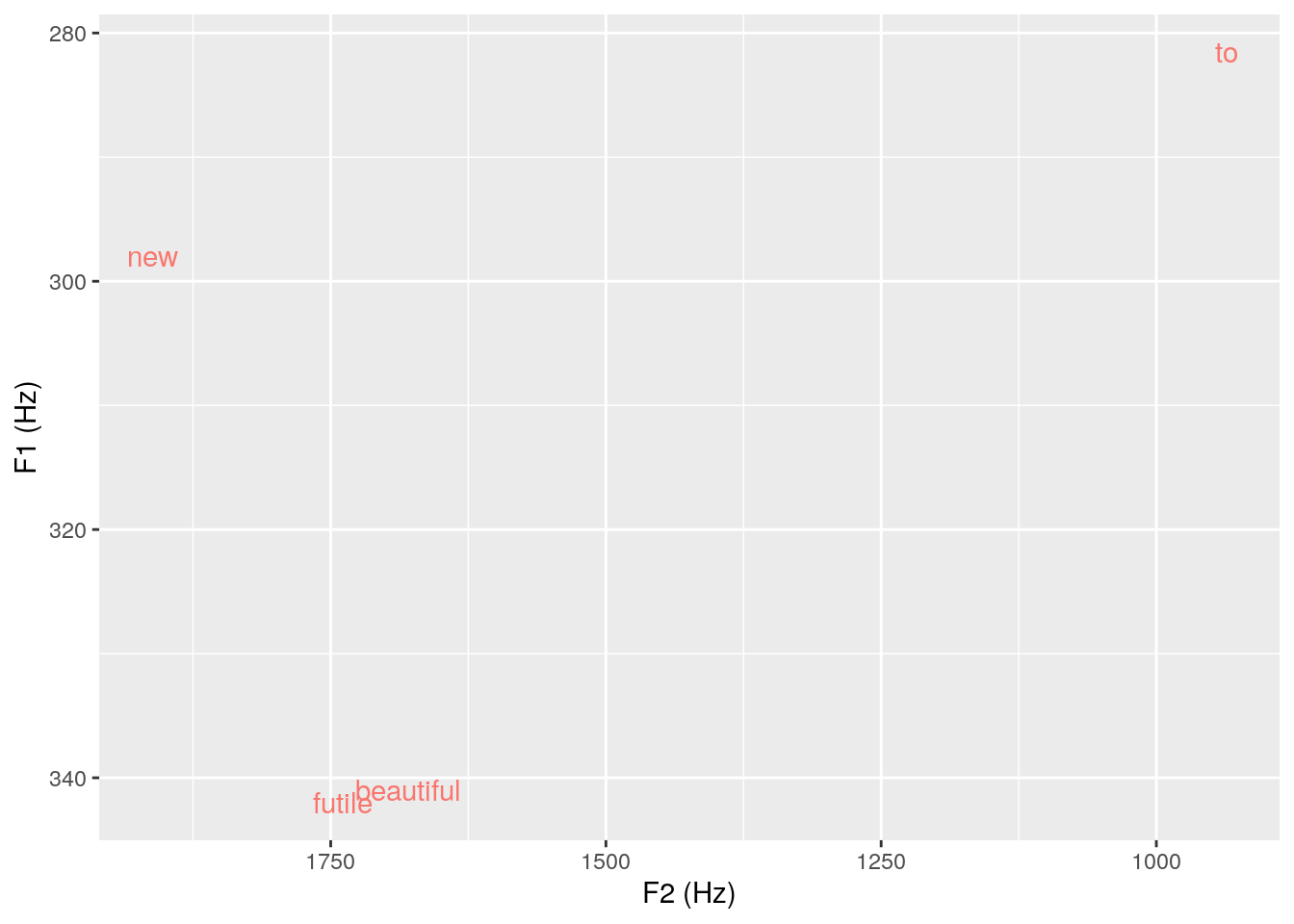
As we can see, the back /u:/ comes from the word “to”, whereas the front vowels are linked to the words “new”, “beautiful”, and “futile”. All three words have in common that /u:/ should be preceded by /j/. This could cause the fronting of /u:/.
However, we should test whether our assumption is true. We will now query the sequences of the preceding consonant and /u:/, and analyse these sequences’ F2 trajectories:
Cu = query(emuDBhandle = ae,
query = "[Phonetic =~ .* -> Phonetic == u:]")
Cu_formants = get_trackdata(ae,
seglist = Cu,
ssffTrackName = "fm")
ggplot(Cu_formants) +
aes(x = times_rel, y = T2, col = labels, group = sl_rowIdx) +
geom_line() +
labs(x = "Duration (ms)", y = "F2 (Hz)")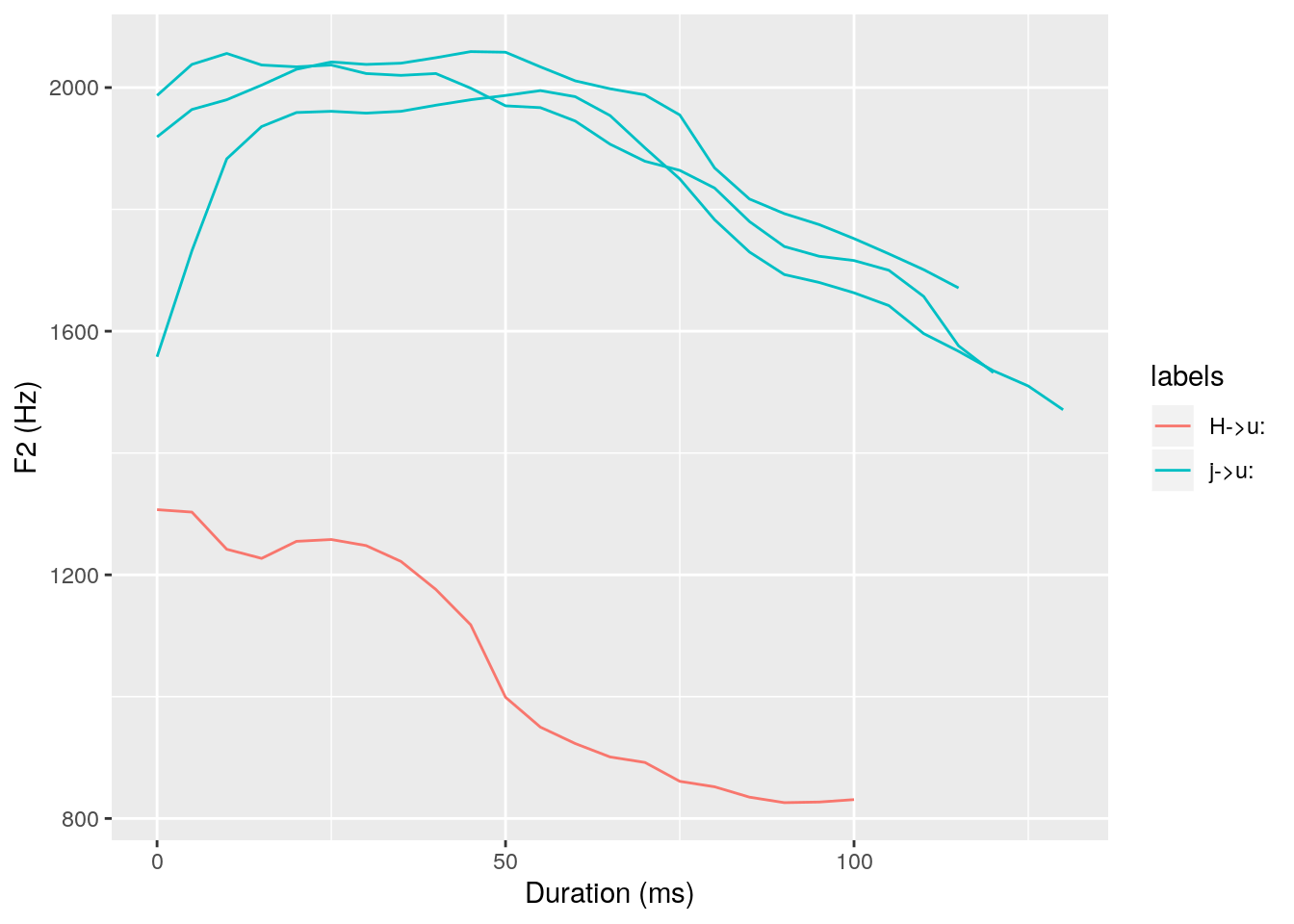
In the word “to”, the preceding segment is labelled “H”, i.e. the aspiration of /t/. You can clearly see in the plot that the F2 trajectory is coming from a relatively high F2 locus, however, this locus is still much lower than F2 in /j/ (which is, of course, very similar to F2 in an /i:/ vowel). Therefore, we can conclude that the preceding /j/ is causing /u:/ to front in that context.
This little analysis was very dependent on several different kinds of queries and re-queries, and we would like to introduce you to the main concepts of these functions:
Simple queries with query()
We will start with very basic queries. The function for conducting queries is simply called query; this functions needs at least two arguments, emuDBhandle and query, e.g.:
V = query(emuDBhandle = ae,
query = "[Phonetic == V]")The expression ["Phonetic == V"] is a legal expression in the EMU Query Language (EQL) (details see below) and could be translated into “which labels in the level Phonetic are equal to the label ‘V’” (and ‘V’ is the SAMPA for English equivalent to IPA /ʌ/, i.e. the vowel in words like <cut>).
Results of query(): segment lists
https://www.phonetik.uni-muenchen.de/~jmh/lehre/sem/ws1819/emuR/LESSON3/pics/annot_struct.png An emuR segment list is a list of segment descriptors. Each segment descriptor describes a sequence of annotation elements. The list is usually a result of an emuDB query using the query function like in the present example. query has found three tokens of [V]:
{kind=link}
V## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 147 147 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 149 149 Phon…
## 3 V 1943. 2037. 0fc618… 0000 msajc… 189 189 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>As of emuR version 2.0.0 this object of the type tibble with one row per segment descriptor:
Data frame columns
labels: labels or sequenced labels of segments concatenated by ‘->’
start: onset time in milliseconds
end: offset time in milliseconds
db_uuid: UUID of emuDB (= a unique identifier)
session: session name
bundle: bundle name (= utterance name)
start_item_id: item ID of first element of sequence
end_item_id: item ID of last element of sequence
level: name of the level that has been searched
attribute: name of attribute that has been searched
start_item_seq_idx: sequence index of start item
end_item_seq_idx: sequence index of end item
type: type of “segment” row:
ITEM: symbolic item,EVENT: event item,SEGMENT: segmentsample_start: start sample position
sample_end: end sample position
sample_rate: sample rate
This makes it easy to access certain informations, e.g.
# get labels:
V$labels## [1] "V" "V" "V"# get start times:
V$start## [1] 187.425 340.175 1943.175# get end times:
V$end## [1] 256.925 426.675 2037.425# calculate durations of the [V]s
V$end - V$start## [1] 69.50 86.50 94.25Inherited times
What happens, if we were looking for a timeless ITEM?
# Phonetic of type SEGMENT, Phoneme of type ITEM
list_levelDefinitions(ae)## name type nrOfAttrDefs attrDefNames
## 1 Utterance ITEM 1 Utterance;
## 2 Intonational ITEM 1 Intonational;
## 3 Intermediate ITEM 1 Intermediate;
## 4 Word ITEM 3 Word; Accent; Text;
## 5 Syllable ITEM 1 Syllable;
## 6 Phoneme ITEM 1 Phoneme;
## 7 Phonetic SEGMENT 1 Phonetic;
## 8 Tone EVENT 1 Tone;
## 9 Foot ITEM 1 Foot;V_phoneme = query(emuDBhandle = ae,
query = "[Phoneme == V]")
V_phoneme## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 114 114 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 116 116 Phon…
## 3 V 1943. 2037. 0fc618… 0000 msajc… 149 149 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>V## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 147 147 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 149 149 Phon…
## 3 V 1943. 2037. 0fc618… 0000 msajc… 189 189 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>As you can see, V and V_phoneme both present times, although Phoneme is a timeless ITEM level. Times are inheritet from the SEGMENT level Phonetic. This, of course, will only work if Phoneme and Phonetic levels are linked (and they are linked, see also Figure 1):
list_linkDefinitions(ae)## type superlevelName sublevelName
## 1 ONE_TO_MANY Utterance Intonational
## 2 ONE_TO_MANY Intonational Intermediate
## 3 ONE_TO_MANY Intermediate Word
## 4 ONE_TO_MANY Word Syllable
## 5 ONE_TO_MANY Syllable Phoneme
## 6 MANY_TO_MANY Phoneme Phonetic
## 7 ONE_TO_MANY Syllable Tone
## 8 ONE_TO_MANY Intonational Foot
## 9 ONE_TO_MANY Foot SyllableIf the ITEM we are interested in was linked to several time-aligned segments, we would have to use query’s parameter timeRefSegmentLevel to choose the segment level from which query derives time information. However, this is not the case here.
The calculation of inherited times can be time-consuming. In many cases, we may not be interested in time information, but only in the labels; we therefore can turn off the calculation of inherited times with an additional parameter: calcTimes = FALSE:
# Phonetic of type SEGEMNT, Phoneme of type ITEM
list_levelDefinitions(ae)## name type nrOfAttrDefs attrDefNames
## 1 Utterance ITEM 1 Utterance;
## 2 Intonational ITEM 1 Intonational;
## 3 Intermediate ITEM 1 Intermediate;
## 4 Word ITEM 3 Word; Accent; Text;
## 5 Syllable ITEM 1 Syllable;
## 6 Phoneme ITEM 1 Phoneme;
## 7 Phonetic SEGMENT 1 Phonetic;
## 8 Tone EVENT 1 Tone;
## 9 Foot ITEM 1 Foot;V_phoneme2 = query(emuDBhandle = ae,
query = "[Phoneme == V]",
calcTimes = FALSE)
V_phoneme2## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V NA NA 0fc618… 0000 msajc… 114 114 Phon…
## 2 V NA NA 0fc618… 0000 msajc… 116 116 Phon…
## 3 V NA NA 0fc618… 0000 msajc… 149 149 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>In this case, all entries in start and end are NA (== Not Available).
requery_hier() and requery_seq()
Relation types
There are two (self-explaining) types of relations in the EMU-SDMS:
dominance
sequence
Dominance
By which words are the “V”s dominated? We could find out by a hierarchical re-query:
#find all "V"-labels in `ae`
V = query(emuDBhandle = ae,
query = "[Phonetic == V]")Now put this segment list into requery_hier() and look for the linked ITEM in level Word, attribute Text:
V_Text = requery_hier(emuDBhandle = ae,
seglist = V,
level = "Text")Your result will be the ITEM labels and calculated times (for the corresponding words).
Sequence
You could also wish to know what “V”s sequential contexts are, e.g. the subsequent segments. We use the sequential structure of the database, and the command requery_seq(), with offset = 1 (offset = -1 would find the sound the precedes ‘V’):
requery_seq(emuDBhandle = ae,
seglist = V,
offset = 1)## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 N 427. 483. 0fc618… 0000 msajc… 150 150 Phon…
## 3 s 2037. 2085. 0fc618… 0000 msajc… 190 190 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>We will discuss both commands more extensively later in the seminar, but wanted to show that it is possible to use the annotation structure and a given segment list to retrieve additional information afterwards. We could use both commands to express more complex queries: e.g. we could look for all “V” within the word “amongst” by querying “V”, then requery all linked words, and then deletin all “V” that are not linked to “amongst”. However, this would be rather cumbersome. A much easier way to conduct more complicated queries is the use of all possibilities of emuR’s query language EQL within the command query. However, before we can use more complex queries, we will have to learn the Emu Query Language.
The Emu Query Language EQL
To learn more about the functionality of the EQL, you can always see the following manual chapter: https://ips-lmu.github.io/The-EMU-SDMS-Manual/chap-querysys.html
As we have seen above, any query must be placed within " ", and any query can be placed within [ ]. You minimally have to give a level, and some sort of representation for a label (this may be a regular expression), unless you do not use one of the position and count functions (see below).
Single argument queries
Equality/inequality/matching/non-matching
Equality
In the examples above, we had looked for the equality of the labels to “V” on the level “Phonetic” (in the database ae):
query(emuDBhandle = ae,
query = "Phonetic == V")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 147 147 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 149 149 Phon…
## 3 V 1943. 2037. 0fc618… 0000 msajc… 189 189 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>So “==” is the equality operator. For backward compatibility with earlier versions of emuR, a single “=” is also allowed (but we ask you to prefer “==” instead):
query(emuDBhandle = ae,
query = "Phonetic == V")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 147 147 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 149 149 Phon…
## 3 V 1943. 2037. 0fc618… 0000 msajc… 189 189 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Inequality
We can also search everything except “V” by the use of !=
query(emuDBhandle = ae,
query = "Phonetic != V")## # A tibble: 250 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 N 427. 483. 0fc618… 0000 msajc… 150 150 Phon…
## 3 s 483. 567. 0fc618… 0000 msajc… 151 151 Phon…
## 4 t 567. 597. 0fc618… 0000 msajc… 152 152 Phon…
## 5 H 597. 674. 0fc618… 0000 msajc… 153 153 Phon…
## 6 @: 674. 740. 0fc618… 0000 msajc… 154 154 Phon…
## 7 f 740. 893. 0fc618… 0000 msajc… 155 155 Phon…
## 8 r 893. 950. 0fc618… 0000 msajc… 156 156 Phon…
## 9 E 950. 1032. 0fc618… 0000 msajc… 157 157 Phon…
## 10 n 1032. 1196. 0fc618… 0000 msajc… 158 158 Phon…
## # … with 240 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>So one way to get ‘everything’ would be to query something that is probably not in your database, like “xyz”. However, there is a much better way: Using so-called regular expressions. To use these, you have to type “=~”, followed by the regular expression, in this case .* (meaning: any character (.) zero or more times (*) ). Although not the focus of this seminar (this example will probably be the only one we will use), knowing the basics of regular expressions can be a very useful tool and it is advisable that you familiarize yourself with them:
everything1 = query(emuDBhandle = ae,
query = "Phonetic != xyz")
everything2 = query(emuDBhandle = ae,
query = "Phonetic =~ .*")
any(everything1 != everything2) # should result in FALSE if both are equal everywhere## [1] FALSEYou can also negate the latter operator by “!~”. An example would be:
# What is the query to retrieve all ITEMs in the “Text” level that don’t begin with ‘a’?
query(emuDBhandle = ae, query = "Text !~ a.*")## # A tibble: 48 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 her 674. 740. 0fc618… 0000 msajc… 24 24 Word
## 2 frien… 740. 1289. 0fc618… 0000 msajc… 30 30 Word
## 3 she 1289. 1463. 0fc618… 0000 msajc… 43 43 Word
## 4 was 1463. 1634. 0fc618… 0000 msajc… 52 52 Word
## 5 consi… 1634. 2150. 0fc618… 0000 msajc… 61 61 Word
## 6 beaut… 2034. 2604. 0fc618… 0000 msajc… 83 83 Word
## 7 it 300. 412. 0fc618… 0000 msajc… 2 2 Word
## 8 is 412. 572. 0fc618… 0000 msajc… 14 14 Word
## 9 futile 572. 1091. 0fc618… 0000 msajc… 21 21 Word
## 10 to 1091. 1222. 0fc618… 0000 msajc… 38 38 Word
## # … with 38 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>So, there are four similar operators, two for equality matching, and two for inequalitiy:
| Symbol | Meaning |
|---|---|
== |
equality |
=~ |
regular expression matching |
!= |
inequality |
!~ |
regular expression non-matching |
The OR operator
Use | to look for one label and another one(s), e.g. ‘m’ or ‘n’ can be retrieved via:
query(emuDBhandle = ae,
query = "Phonetic == m | n")## # A tibble: 19 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 n 1032. 1196. 0fc618… 0000 msajc… 158 158 Phon…
## 3 n 1741. 1791. 0fc618… 0000 msajc… 168 168 Phon…
## 4 n 1515. 1554. 0fc618… 0000 msajc… 170 170 Phon…
## 5 n 2431. 2528. 0fc618… 0000 msajc… 184 184 Phon…
## 6 n 895. 1023. 0fc618… 0000 msajc… 158 158 Phon…
## 7 m 1490. 1565. 0fc618… 0000 msajc… 169 169 Phon…
## 8 n 2402. 2475. 0fc618… 0000 msajc… 182 182 Phon…
## 9 m 497. 559. 0fc618… 0000 msajc… 188 188 Phon…
## 10 n 2227. 2271. 0fc618… 0000 msajc… 216 216 Phon…
## 11 n 3046. 3068. 0fc618… 0000 msajc… 229 229 Phon…
## 12 m 1587. 1656. 0fc618… 0000 msajc… 149 149 Phon…
## 13 m 819. 903. 0fc618… 0000 msajc… 120 120 Phon…
## 14 n 1435. 1495. 0fc618… 0000 msajc… 127 127 Phon…
## 15 n 1775. 1834. 0fc618… 0000 msajc… 132 132 Phon…
## 16 n 509. 544. 0fc618… 0000 msajc… 166 166 Phon…
## 17 m 1630. 1709. 0fc618… 0000 msajc… 185 185 Phon…
## 18 m 2173. 2233. 0fc618… 0000 msajc… 194 194 Phon…
## 19 n 2448. 2480. 0fc618… 0000 msajc… 199 199 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>You can expand this as well:
query(emuDBhandle = ae,
query = "Phonetic == m | n | N")## # A tibble: 23 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 N 427. 483. 0fc618… 0000 msajc… 150 150 Phon…
## 3 n 1032. 1196. 0fc618… 0000 msajc… 158 158 Phon…
## 4 n 1741. 1791. 0fc618… 0000 msajc… 168 168 Phon…
## 5 n 1515. 1554. 0fc618… 0000 msajc… 170 170 Phon…
## 6 n 2431. 2528. 0fc618… 0000 msajc… 184 184 Phon…
## 7 n 895. 1023. 0fc618… 0000 msajc… 158 158 Phon…
## 8 m 1490. 1565. 0fc618… 0000 msajc… 169 169 Phon…
## 9 n 2402. 2475. 0fc618… 0000 msajc… 182 182 Phon…
## 10 m 497. 559. 0fc618… 0000 msajc… 188 188 Phon…
## # … with 13 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>This functionality can also be achieved using regular expressions.
Complex queries
Sequencial and dominance queries
Bracketing
In all hierarchical queries, bracketing with [ ] is required to structure your query. In simple queries, however, brackets are optional.
mnN = query(emuDBhandle = ae,
query = "[Phonetic == m | n | N]")However, this sequential query will fail, because of missing brackets:
query(ae, "Phonetic == V -> Phonetic == m")"[Phonetic == V -> Phonetic == m]" would be the correct EQL expression in this case.
Sequential queries
Use the -> operator to find sequences of segments:
query(ae, "[Phonetic == V -> Phonetic == m]")## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V->m 187. 340. 0fc618… 0000 msajc… 147 148 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Note: all row entries in the resulting segment list have the start time of “V”, the end time of “m” and their labels will be “V->m”. You can change this with the so-called result modifier hash tag “#”:
query(ae, "[#Phonetic == V -> Phonetic == m]") # finds V, if V is followed by m## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 147 147 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>query(ae, "[Phonetic == V -> #Phonetic == m]") # finds m, if m is preceded by V## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Keep in mind that only one hash tag per query is allowed.
You can search sequences of sequences, however, you have to use bracketing; otherwise, you get an error like in
query(ae, "[Phonetic == @ -> Phonetic == n -> Phonetic == s]")The correct code would be:
query(ae, "[[Phonetic == @ -> Phonetic == n ] -> Phonetic == s]")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 @->n-… 1715. 1893. 0fc618… 0000 msajc… 167 169 Phon…
## 2 @->n-… 2382. 2754. 0fc618… 0000 msajc… 183 185 Phon…
## 3 @->n-… 2201. 2409. 0fc618… 0000 msajc… 215 217 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>A much more complex example would be:
## What is the query to retrieve all sequences of ITEMs containing labels “offer” followed by two arbitrary labels followed by “resistance”?
query(ae, "[[[Text == offer -> Text =~ .*] -> Text =~ .* ] -> Text == resistance]")## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 offer… 1958. 2754. 0fc618… 0000 msajc… 48 80 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Domination queries
Use the operator ^ for all queries, in which two linked levels are involved; e.g.
list_linkDefinitions(ae)## type superlevelName sublevelName
## 1 ONE_TO_MANY Utterance Intonational
## 2 ONE_TO_MANY Intonational Intermediate
## 3 ONE_TO_MANY Intermediate Word
## 4 ONE_TO_MANY Word Syllable
## 5 ONE_TO_MANY Syllable Phoneme
## 6 MANY_TO_MANY Phoneme Phonetic
## 7 ONE_TO_MANY Syllable Tone
## 8 ONE_TO_MANY Intonational Foot
## 9 ONE_TO_MANY Foot Syllable## What is the query to retrieve all ITEMs containing the label “p” in the “Phoneme” level that occur in strong syllables (i.e. dominated by / linked to ITEMs of the level “Syllable” that contain the label “S” (== STRONG, as opposed to "W" == WEAK))?
query(ae, "[Phoneme == p ^ Syllable == S]")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 p 559. 640. 0fc618… 0000 msajc… 147 147 Phon…
## 2 p 1656. 1699. 0fc618… 0000 msajc… 122 122 Phon…
## 3 p 864. 970. 0fc618… 0000 msajc… 136 136 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>However, the operator is not directional; although “Syllable” dominates “Phoneme”, you could have asked
query(ae, "[Syllable == S ^ #Phoneme == p]")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 p 559. 640. 0fc618… 0000 msajc… 147 147 Phon…
## 2 p 1656. 1699. 0fc618… 0000 msajc… 122 122 Phon…
## 3 p 864. 970. 0fc618… 0000 msajc… 136 136 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>So, “^” should not be translated with “is dominated by”, but rather into “is linked to”. However, you have to use the hash tag in order to get labels and times of the Phoneme level here. You can leave out the hash tag if the level you are interested in is the first one in your question.
You can query multiple dominations, however, like in the sequencing case, you have to use brackets:
# What is the query to retrieve all ITEMs on the “Phonetic” level that are part of a strong syllable (labeled “S”) and belong to the words “amongst” or “beautiful”?
query(ae, "[[Phonetic =~ .* ^ Syllable == S] ^ Text == amongst | beautiful]")## # A tibble: 9 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 149 149 Phon…
## 3 N 427. 483. 0fc618… 0000 msajc… 150 150 Phon…
## 4 s 483. 567. 0fc618… 0000 msajc… 151 151 Phon…
## 5 t 567. 597. 0fc618… 0000 msajc… 152 152 Phon…
## 6 H 597. 674. 0fc618… 0000 msajc… 153 153 Phon…
## 7 db 2034. 2150. 0fc618… 0000 msajc… 173 173 Phon…
## 8 j 2150. 2211. 0fc618… 0000 msajc… 174 174 Phon…
## 9 u: 2211. 2284. 0fc618… 0000 msajc… 175 175 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int># same as
query(ae, "[[#Phonetic =~ .* ^ Syllable == S] ^ Text == amongst | beautiful]")## to get the "Text"-items instead, use
query(ae, "[[Phonetic =~ .* ^ Syllable == S] ^ #Text == amongst | beautiful]")## # A tibble: 2 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 among… 187. 674. 0fc618… 0000 msajc… 2 2 Word
## 2 beaut… 2034. 2604. 0fc618… 0000 msajc… 83 83 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Functions
The are three position functions and one count function. As the latter function results in a number, queries involve a comparison with a number (by using one of “==”, “!=”, “>”, “>=”, “<”, “<=”, see below); The result of the position functions is logical; we therefore ask, whether a certain condition is TRUE or FALSE.
Position functions
There are three position functions, Start(), Medial(), and End(). Example queries are:
## What is the query to retrieve all word-initial syllables?
## (NB: syllable labels are either "W" or "S")
query(ae, "[Start(Word, Syllable) == TRUE]")## # A tibble: 54 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 W 187. 257. 0fc618… 0000 msajc… 102 102 Syll…
## 2 S 674. 740. 0fc618… 0000 msajc… 104 104 Syll…
## 3 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 4 W 1289. 1463. 0fc618… 0000 msajc… 106 106 Syll…
## 5 W 1463. 1634. 0fc618… 0000 msajc… 107 107 Syll…
## 6 W 1634. 1791. 0fc618… 0000 msajc… 108 108 Syll…
## 7 S 2034. 2284. 0fc618… 0000 msajc… 111 111 Syll…
## 8 W 300. 412. 0fc618… 0000 msajc… 105 105 Syll…
## 9 W 412. 572. 0fc618… 0000 msajc… 106 106 Syll…
## 10 S 572. 798. 0fc618… 0000 msajc… 107 107 Syll…
## # … with 44 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>Examples for Medial() and End() are:
## What is the query to retrieve all word-medial syllables?
query(ae, "[Medial(Word, Syllable) == TRUE]")## # A tibble: 9 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 1791. 1945. 0fc618… 0000 msajc… 109 109 Syll…
## 2 W 2284. 2362. 0fc618… 0000 msajc… 112 112 Syll…
## 3 S 2078. 2228. 0fc618… 0000 msajc… 117 117 Syll…
## 4 W 2220. 2305. 0fc618… 0000 msajc… 116 116 Syll…
## 5 W 2305. 2534. 0fc618… 0000 msajc… 117 117 Syll…
## 6 W 640. 707. 0fc618… 0000 msajc… 131 131 Syll…
## 7 S 2271. 2502. 0fc618… 0000 msajc… 137 137 Syll…
## 8 W 3046. 3123. 0fc618… 0000 msajc… 141 141 Syll…
## 9 W 2037. 2173. 0fc618… 0000 msajc… 122 122 Syll…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>## What is the query to retrieve all word-final syllables?
query(ae, "[End(Word, Syllable) == TRUE]")## # A tibble: 54 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## 2 S 674. 740. 0fc618… 0000 msajc… 104 104 Syll…
## 3 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 4 W 1289. 1463. 0fc618… 0000 msajc… 106 106 Syll…
## 5 W 1463. 1634. 0fc618… 0000 msajc… 107 107 Syll…
## 6 W 1945. 2150. 0fc618… 0000 msajc… 110 110 Syll…
## 7 W 2362. 2604. 0fc618… 0000 msajc… 113 113 Syll…
## 8 W 300. 412. 0fc618… 0000 msajc… 105 105 Syll…
## 9 W 412. 572. 0fc618… 0000 msajc… 106 106 Syll…
## 10 S 798. 1091. 0fc618… 0000 msajc… 108 108 Syll…
## # … with 44 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>## What is the query to retrieve all word-final syllables?
head(query(ae, "[End(Word, Syllable) == TRUE]"))## # A tibble: 6 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## 2 S 674. 740. 0fc618… 0000 msajc… 104 104 Syll…
## 3 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 4 W 1289. 1463. 0fc618… 0000 msajc… 106 106 Syll…
## 5 W 1463. 1634. 0fc618… 0000 msajc… 107 107 Syll…
## 6 W 1945. 2150. 0fc618… 0000 msajc… 110 110 Syll…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Everything not being first or last element is medial:
query(ae, "[Medial(Word, Phoneme) == TRUE]")## # A tibble: 114 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 115 115 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 116 116 Phon…
## 3 N 427. 483. 0fc618… 0000 msajc… 117 117 Phon…
## 4 s 483. 567. 0fc618… 0000 msajc… 118 118 Phon…
## 5 r 893. 950. 0fc618… 0000 msajc… 122 122 Phon…
## 6 E 950. 1032. 0fc618… 0000 msajc… 123 123 Phon…
## 7 n 1032. 1196. 0fc618… 0000 msajc… 124 124 Phon…
## 8 @ 1506. 1548. 0fc618… 0000 msajc… 129 129 Phon…
## 9 @ 1715. 1741. 0fc618… 0000 msajc… 132 132 Phon…
## 10 n 1741. 1791. 0fc618… 0000 msajc… 133 133 Phon…
## # … with 104 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>head(query(ae, "[Medial(Word, Phoneme) == TRUE]"))## # A tibble: 6 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 115 115 Phon…
## 2 V 340. 427. 0fc618… 0000 msajc… 116 116 Phon…
## 3 N 427. 483. 0fc618… 0000 msajc… 117 117 Phon…
## 4 s 483. 567. 0fc618… 0000 msajc… 118 118 Phon…
## 5 r 893. 950. 0fc618… 0000 msajc… 122 122 Phon…
## 6 E 950. 1032. 0fc618… 0000 msajc… 123 123 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Count function
The count function’s name is Num(). Num(x,y) counts how many y are in x. You can therefore ask things like the following:
## What is the query to retrieve all words that contain two syllables?
query(ae, "[Num(Text, Syllable) == 2]")## # A tibble: 11 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 among… 187. 674. 0fc618… 0000 msajc… 2 2 Word
## 2 futile 572. 1091. 0fc618… 0000 msajc… 21 21 Word
## 3 any 1437. 1628. 0fc618… 0000 msajc… 58 58 Word
## 4 furth… 1628. 1958. 0fc618… 0000 msajc… 68 68 Word
## 5 shiver 1651. 1995. 0fc618… 0000 msajc… 70 70 Word
## 6 itches 300. 662. 0fc618… 0000 msajc… 2 2 Word
## 7 always 775. 1280. 0fc618… 0000 msajc… 28 28 Word
## 8 tempt… 1401. 1806. 0fc618… 0000 msajc… 51 51 Word
## 9 displ… 667. 1211. 0fc618… 0000 msajc… 25 25 Word
## 10 attra… 1211. 1579. 0fc618… 0000 msajc… 44 44 Word
## 11 ever 2480. 2795. 0fc618… 0000 msajc… 106 106 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>## What is the query to retrieve all syllables that contain more than four phonemes?
query(ae, "[Num(Syllable, Phoneme) > 4]")## # A tibble: 7 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## 2 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 3 W 2228. 2754. 0fc618… 0000 msajc… 118 118 Syll…
## 4 S 1213. 1797. 0fc618… 0000 msajc… 134 134 Syll…
## 5 S 1890. 2470. 0fc618… 0000 msajc… 105 105 Syll…
## 6 S 1964. 2554. 0fc618… 0000 msajc… 90 90 Syll…
## 7 S 1248. 1579. 0fc618… 0000 msajc… 119 119 Syll…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>Conjunction
You can use & to search within several attribute definitions on the same level. For example, the level Word in ae has several attribute definitions
list_attributeDefinitions(ae, level = "Word")## name level type hasLabelGroups hasLegalLabels
## 1 Word Word STRING FALSE FALSE
## 2 Accent Word STRING FALSE FALSE
## 3 Text Word STRING FALSE FALSEWe could, therefore, look for all accented (“S”) words
query(ae, "[Text =~.* & Accent == S]")## # A tibble: 25 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 among… 187. 674. 0fc618… 0000 msajc… 2 2 Word
## 2 frien… 740. 1289. 0fc618… 0000 msajc… 30 30 Word
## 3 beaut… 2034. 2604. 0fc618… 0000 msajc… 83 83 Word
## 4 futile 572. 1091. 0fc618… 0000 msajc… 21 21 Word
## 5 furth… 1628. 1958. 0fc618… 0000 msajc… 68 68 Word
## 6 resis… 1958. 2754. 0fc618… 0000 msajc… 80 80 Word
## 7 chill 380. 745. 0fc618… 0000 msajc… 13 13 Word
## 8 wind 745. 1083. 0fc618… 0000 msajc… 23 23 Word
## 9 caused 1083. 1456. 0fc618… 0000 msajc… 36 36 Word
## 10 shiver 1651. 1995. 0fc618… 0000 msajc… 70 70 Word
## # … with 15 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>Another usage of “&” is to combine a basic query with a function, e.g.
## What is the query to retrieve all non-word-final “S” syllables?
query(ae, "[[Syllable == S & End(Word, Syllable) == FALSE] ^ #Text=~.*]")## # A tibble: 16 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 consi… 1634. 2150. 0fc618… 0000 msajc… 61 61 Word
## 2 beaut… 2034. 2604. 0fc618… 0000 msajc… 83 83 Word
## 3 futile 572. 1091. 0fc618… 0000 msajc… 21 21 Word
## 4 any 1437. 1628. 0fc618… 0000 msajc… 58 58 Word
## 5 furth… 1628. 1958. 0fc618… 0000 msajc… 68 68 Word
## 6 resis… 1958. 2754. 0fc618… 0000 msajc… 80 80 Word
## 7 shiver 1651. 1995. 0fc618… 0000 msajc… 70 70 Word
## 8 viole… 1995. 2692. 0fc618… 0000 msajc… 82 82 Word
## 9 empha… 425. 1129. 0fc618… 0000 msajc… 13 13 Word
## 10 conce… 2104. 2694. 0fc618… 0000 msajc… 78 78 Word
## 11 weakn… 2781. 3457. 0fc618… 0000 msajc… 109 109 Word
## 12 itches 300. 662. 0fc618… 0000 msajc… 2 2 Word
## 13 always 775. 1280. 0fc618… 0000 msajc… 28 28 Word
## 14 tempt… 1401. 1806. 0fc618… 0000 msajc… 51 51 Word
## 15 custo… 1824. 2368. 0fc618… 0000 msajc… 73 73 Word
## 16 ever 2480. 2795. 0fc618… 0000 msajc… 106 106 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>