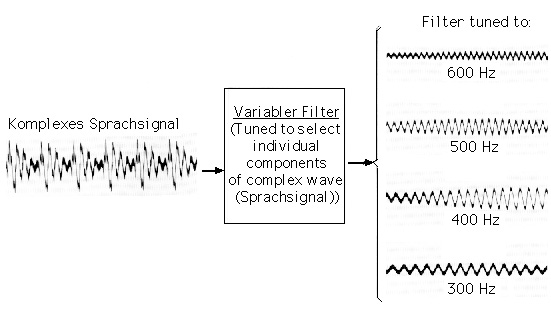
Abb. 1.1: Variabler Filter zerlegt das Sprachsignal in seine spektralen Komponenten
Abbildung 1.1 demonstriert das Prinzip der Zerlegung eines komplexen Sprachsignals mittels eines variablen Filters (entnommen aus POTTER, KOPP und GREEN, 1947).
Der klassische Sonagraph
Der klassische Sonagraph ist ein elektromechanisches Gerät zur Aufzeichnung von zeitvarianten Fourierspektren, welches auf elegante Weise die drei Grundfunktionen Bandpaßfilterung, Gleichrichtung und Glättung mit der graphischen Darstellung verbindet.Bei der Arbeit mit dem klassischen Kay-Sonagraphen kann eine Äußerung von maximal 2,4 Sekunden aufgezeichnet werden. Das gespeicherte Sprachsignal kann beliebig oft abgehört und als Sonagramm im Frequenzbereich 0-8000 Hz zu Papier gebracht werden.
Die Bedienung des klassischen Sonagraphen geschieht in folgenden Schritten:
- Mit Drücken des Aufnahmeknopfes kann aufgesprochen werden.
- Gespeichert werden jeweils die letzten 2,4 Sekunden vor Aufnahmeende.
- Der Anfang der Aufnahme wird akustisch durch Überlagerung eines 500 Hz-Piepstones gekennzeichnet, der gleichzeitig die Frequenzachse skaliert.
- Vor der Aufzeichnung auf Papier wird die gewünschte Analyse-Bandbreite gewählt. Bei der Wahl einer Filter-Bandbreite von 350 Hz entsteht ein Breitband-Sonagramm, bei einem Filter von 80 Hz ein Schmalband-Sonagramm.
- Zur Aufzeichnung wird ein Papier um die Trommel gelegt und mechanisch fixiert. Bei dem Papier handelt es sich um spezielles Thermopapier, das durch elektrische Signale geschwärzt wird.
Demo:
Dieses Prinzip wollen wir in der folgenden Abbildung demonstrieren.
Sobald Sie den Audio-Button anklicken, hören Sie, was im abgebildeten
Sonagramm gesprochen wurde. Gleichzeitig läuft ein Cursor durch
das Sonagramm, der immer die Stelle anzeigt, die gerade abgehört
wird.

Der digitale Sonagraph
Mittlerweile werden anstelle des klassischen KAY-Sonagraphen zunehmend digitale Verfahren benutzt. Darunter spielt die Diskrete-Fourier-Transformation (DFT), in der Regel als Fast-Fourier-Transformation-Algorithmus (FFT) implementiert, die Hauptrolle.Alle in diesem Dokument enthaltenen Sonagramme wurden - sofern nicht anders gekennzeichnet - mit dem digitalen KAY-Sonagraphen Modell 5500 erstellt.
Bei dem digitalen KAY-Sonagraphen Modell 5500, einem Echtzeit-Sonagraphen, handelt es sich um eine Signal-Analyse-Workstation mit frei wählbaren und vielfältig kombinierbaren Analysemöglichkeiten. Die Workstation 5500 besteht aus einer Rechnereinheit, mindestens einem Lautsprecher, einem Bildschirm, einem Mikrophon oder Tonband-/Cassettengerät und einem Drucker. Es kann ein Sprachsignal von einer Länge bis zu 98 Sekunden aufgezeichnet werden.
Das entstandene Sonagramm kann als Ganzes oder in mittels Cursor markierten Teilen abgehört und ausgedruckt werden. Die gleichzeitige Darstellung von Breitband- und Schmalband-Sonagramm in zwei Fenstern auf dem Bildschirm ist möglich. Neben den bekannten Analysefilter-Bandbreiten, 300 Hz und 50 Hz, können weitere Filter gewählt werden. Die gewünschten Parameter für Aufnahme, Analyse, Bildschirm-Anzeige und Ausdruck werden über vorgegebene oder selbstdefinierte Setups festgelegt und ermöglichen so ein sehr individuelles Arbeiten.
Vertiefung zur Handhabung des Sonagraphen.
Das Sonagramm stellt das Sprachsignal in drei akustischen
Dimensionen (Parameter) dar:
Jede vertikale Linie im Sonagramm entspricht einem Glottisschlag,
d.h. einer glottalen Verschlußbildung. Sie kennzeichnen die Stimmhaftigkeit des Sprachsignals. Die Abstände
dieser vertikalen Linien zeigen die Frequenz der Glottisschläge
an. Daraus lassen sich Frequenzänderungen im Verlauf des
Sprachsignals ablesen, wie z. B. ein "Knarzen" der Stimme (creaky),
der äußerungsfinale Tonhöhenabfall oder steigende
Tonhöhe am Ende eines Fragesatzes. Eine Ausnahme bildet der Burst
eines Plosivs, der ebenfalls häufig als vertikale Linie im
Sonagramm zu sehen ist
Ein Schmalband-Sonagramm bietet dagegen eine hohe Auflösung im
Frequenzbereich und erfaßt demzufolge den Tonhöhenverlauf sowie
die Lage und den Verlauf der Harmonischen (Obertöne).
Als Regel gemäß der
Heisenberg'schen Unschärferelation gilt: Je genauer die
Auflösung im Zeitbereich, desto ungenauer ist sie im
Frequenzbereich, und umgekehrt. Eine hohe Frequenz- und
Zeitauflösung zu erreichen, ist schwierig, da der Analysefilter
entweder eine hohe Frequenz- oder eine hohe Zeitauflösung
ermöglicht.
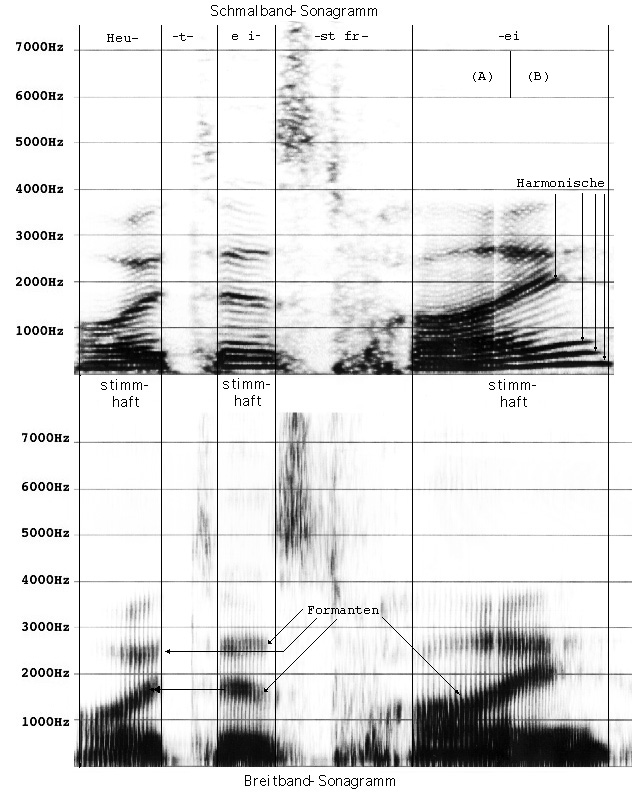
Das Sonagramm in Abbildung 1.2 zeigt das Sonagramm der Frage "Heute ist frei?". Im Schmalband-Sonagramm ist eine steigende Tonhöhe anhand der steigenden Obertöne auf der ersten Silbe /Heu-/ sowie am Äußerungsende auf dem Diphthong /ei/ zu erkennen.
Abb. 1.2: Schmalband- und Breitband-Sonagramm mit Frageintonation
und Markierung von stimmhaften Segmenten
Bei den Plosiven ist Stimmhaftigkeit im Sonagramm erkennbar am sog.
'voice bar', einem schwarzen Balken im untersten
Frequenzbereich. (Nicht zu verwechseln mit dem Grundrauschen. Dies
ist bedingt durch Hintergrundgeräusche bei der Aufnahme, die
auch von der Analyse-Workstation selbst, z.B. dem Bildschirm,
stammen können.)
In obiger Abbildung sind stimmhafte und stimmlose Segmente
entsprechend gekennzeichnet.
Im Schmalband-Sonagramm kann mit Hilfe der Harmonischen die Grundfrequenz ermittelt werden:
Beispiel:
Abb. 1.2a: Schmalband- und Breitband-Sonagramm von "Baum" mit Frageintonation zur Berechnung der Grundfrequenz. Die für die Berechnung der Grundfrequenz relevanten Harmonischen sind mit Punkten markiert.
Bei einer typischen mittleren Silbenfrequenz von 3 Hz, d.h. drei
Silben pro Sekunde, beträgt die Silbendauer ca. 330 ms.
Die Dauer eines Sprachlauts liegt in der Regel zwischen 30 ms und
150 ms.
Das Bewußtsein, daß artikulatorische Prozesse nie abrupt,
sondern immer kontinuierlich ablaufen, ist daher eine wichtige
Voraussetzung für das erfolgreiche Lesen von Sonagrammen.
Nicht Einzellaute werden produziert, sondern ein Lautstrom, in dem
die Laute koartikulatorisch miteinander verbunden sind. Die
Artikulationsorgane sind dabei ständig in Bewegung. Sie
verharren nicht oder nur sehr kurz in der definierten
Artikulationsposition, sondern bewegen sich zu dieser Position hin,
um dann bereits die nächste Position anzusteuern.
Dabei können die Übergangsphasen im Sonagramm den
Hauptbestandteil des Lautes ausmachen. Auch kann ein Laut - in
unterschiedlichen Lautkontexten oder von verschiedenen Sprechern
produziert - immer wieder etwas anders aussehen.
Bei der Artikulation kurzer Vokale in entsprechender
Umgebung kann es zum sog. 'duration dependent undershoot'
(vgl. Lindblom, 1963) kommen. Die Vokalphase ist dabei so kurz,
daß die Artikulationsendposition des Vokals nicht erreicht
wird, da die Artikulationsorgane bereits die Position des
nächsten, artikulatorisch weit entfernten Lautes ansteuern.
Die Artikulationsorgane sind beim Sprechen nicht nur ständig in
Bewegung, sondern ihre Bewegungen überlagern sich. Während
ein Laut artikuliert wird, zeigt er möglicherweise noch
Eigenschaften des vorausgehenden Lautes, stellt sich aber bereits
auf die Artikulation des folgenden ein. Demzufolge finden sich auch
im akustischen Resultat dieser Äußerung in jedem Laut -
mehr oder weniger stark ausgeprägt - gewisse Merkmale der
angrenzenden Laute.
Beispiele:
Man stelle sich dazu nur die Aktivität der Zunge bei einem
bilabialen Plosiv /b, p/, gefolgt von einem Vokal vor: noch
während der Verschlußphase des Plosivs kann die Zunge
bereits die Vokalposition des Folgevokals einnehmen.
Wie aber gehen wir nun mit dem komplexen Bündel von
akustischen Eigenschaften um, die jedem koartikulierten Laut zu
eigen sind? Welche Strategien sind notwendig, um sich sowohl die
für den Laut typischen als auch die durch Koartikulation
bedingten Eigenschaften anzueignen und, was noch wichtiger ist,
sie unterscheiden zu können?
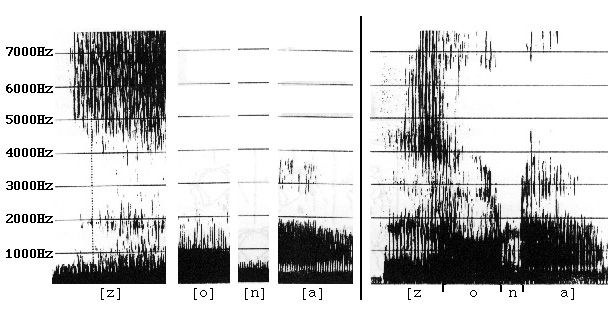
So wenig, wie die Lautfolge [z o n a], die beiden ersten Silben des
Wortes "Sonagramm", perzeptiv der Aneinanderreihung von Einzellauten
[z], [o], [n], [a] entspricht (vgl. Abb. 1.3), werden wir das Sonagramm
einer natürlichsprachlichen Äußerung mit einer Folge
isoliert gesprochener Einzellaute vergleichen können. Dennoch
vermögen wir, aufgrund der Kenntnis dieser Einzellaute, die
Lautfolge perzeptiv in ihre Einzellaute zu
zerlegen. Dieser Vorgang ist uns aus der Transkription bekannt.
Analog wollen wir nun hier vorgehen.
Abb. 1.3: [z], [o], [n], [a] vs. [zona]
Wenn wir Sonagramme lesen wollen, müssen wir uns natürlich
fragen, ob das aus den artikulatorischen Bewegungen resultierende
akustische Signal erkenn- und isolierbare Segmente möglichst
phonemischen Charakters enthält, die wir mit entsprechenden
Labeln versehen können.
Wir versuchen, diese Frage pragmatisch zu beantworten, indem wir
einen kleinen Test machen.
Test:
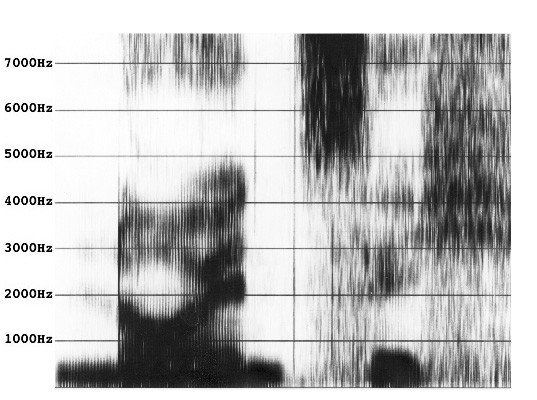
Versuchen Sie das folgende Sonagramm nach rein äußerlichen
Kriterien intuitiv in Segmente zu unterteilen.
Abb. 1.4: Nicht segmentiertes Sonagramm mit segmentierbarer
Lautsequenz
Für die Sonagramm-Darstellung können wir die Frage
offensichtlich bejahen. Ob die Grenzen nun exakt oder nur
ungefähr bestimmbar sind, ist ein zweitrangiges Problem, das uns
als Sonagramm-Leser nur begrenzt interessieren muß.
Das oben abgebildete Sonagramm zeigt eine Sequenz von diskreten,
segmentierbaren Zuständen, die zudem noch phonologischen
Einheiten entsprechen.
Auch wenn die Vokalsegmente starke Transitionen (die beiden Vokalteile eines
Diphthongs werden üblicherweise nicht getrennt) aufweisen, sind doch
deutliche Segmentgrenzen zu ziehen zwischen Vokal, Nasal, Frikativ und Plosiv.
Zweifellos haben einige Lauttypen von Natur aus Transitionscharakter wie z.B.
Aspiration, Approximanten oder Diphthonge. Dennoch sind ihre ungefähren
Anfangs- und Endgrenzen erfahrungsgemäß bestimmbar.
Für uns genügt es vollkommen, die Anzahl der Segmente bestimmen zu
können und die gefundenen Segmente zu klassifizieren. Zur Kennzeichnung
der Segmente verwenden wir die aus der Transkription bekannten
artikulatorischen Label. Konsonanten werden durch Artikulationsmodus und
-stelle beschrieben und Vokale anhand ihrer Zungenhöhe (hoch-tief) und
-position (vorn, zentral, hinten) und eventueller Lippenrundung
klassifiziert.
Vertiefung zur Segmentation
Das Spektrum: Zeit - Frequenz - Intensität
Breitband- vs. Schmalband-Sonagramm
Ein Breitband-Sonagramm bietet einer hohen Auflösung
im Zeitbereich, d.h. die einzelnen Glottisschläge sind gut
sichtbar und man kann die Formantstruktur der Vokale gut verfolgen.
Die dabei verwendeten 'Kurzzeit'-FFTs sorgen für eine hohe
Zeitauflösung, um schnell wechselnde Ereignisse zu erfassen.
Diese Zeitauflösung ist hoch genug, um Glottisimpulse unter
300 Hz aufzulösen und ebenfalls ideal für die
Formantauflösung. Formanten sind als waagerechte Frequenzbänder im Sonagramm zu sehen.
Diese Harmonischen sind im Sonagramm als schmale, parallele "Bänder" zu erkennen,
die grundsätzlich parallel verlaufen und deren Abstand jeweils gleich groß ist. Dieser Abstand kann zu verschiedenen Zeitpunkten variieren. Zu einem Zeitpunkt jedoch ist der Abstand von der ersten zur zweiten und weiter zur dritten und vierten Harmonischen immer gleich groß.
Die Obertöne sollten aber auf keinen Fall mit den Formanten verwechselt werden, wenngleich sie im Sonagramm ähnlich aussehen. Im Frequenzbereich der Formanten sind die Harmonischen besonders gut zu erkennen durch ihren hohen Schwärzungsgrad.
Zur Stimmhaftigkeit
Stimmhafte Laute sind im Sonagramm erkennbar an den
Glottisschlägen. Fehlen sie, handelt es sich um einen stimmlosen
oder entstimmten Laut. Die Glottisschläge können
annähernd über den gesamten Frequenzbereich als durchgehende
Linien sichtbar sein wie bei den Vokalen, oder aber nur im untersten
Frequenzbereich unterhalb von etwa 500 Hz wie beispielsweise bei
stimmhaften Plosiven.
Grundfrequenz und zeitliche Orientierung im Sonagramm
Bei einer Grundfrequenz F0 von 100 Hz beträgt der Abstand
der im Sonagramm sichtbaren Glottisschläge 10 ms. Somit
beträgt die Dauer der größten, im Zeitsignal
erkennbaren Schwingungsperiode 10 ms. Die
Schwingungsperiodendauern und damit der Abstand der
Glottisschläge bei verschiedenen Grundfrequenzen können
der folgenden Tabelle entnommen werden. Die Periodendauer T
errechnet sich aus dem Kehrwert der Grundfrequenz F0:
Grundfrequenz F0 Abstand der Glottisschläge
Periodendauer T
80 Hz 12,5 ms
100 Hz 10,0 ms
150 Hz 6,7 ms
200 Hz 5,0 ms
250 Hz 4,0 ms
Tabelle: Grundfrequenz und Periodendauer
Man zählt die Anzahl der Harmonischen in einem bestimmten Frequenzbereich,
z.B. von 0 bis 1000 Hz. Dann dividiert man den Frequenzbereich, hier: 1000 Hz durch die Anzahl der gefundenen Harmonischen in diesem Bereich und erhält die Grundfrequenz in Hz.
Betrachten wir in Abbildung 1.2a den ersten Abschnitt (A). Im Bereich von 0 - 1000 Hz finden wir sechs Harmonische (mit Punkten markiert). Dividieren wir 1000 Hz : 6, erhalten wir eine Grundfrequenz von 167 Hz im Bereich (A).
Im letzten Abschnitt (B) finden wir im Bereich von 0 - 1000 Hz zwei Harmonische (mit Punkten markiert) und erhalten so eine Grundfrequenz von 500 Hz.
Wir sehen, daß im Abschnitt (A) der Abbildung die Harmonischen wesentlich enger zusammen liegen, d.h. die Grundfrequenz ist dort deutlich tiefer. Parallel dazu entdecken wir im Breitband-Sonagramm, daß die Glottischläge in Abschnitt (B) näher beieinander liegen, was unsere Beobachtung im Schmalband-Sonagramm bestätigt. 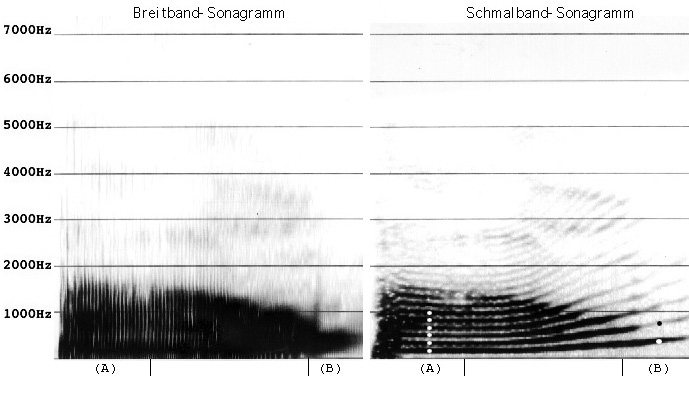
Zur Orientierung auf der Frequenzachse
Der im Sonagramm dargestellte Frequenzbereich geht üblicherweise
von 0-8000 Hz, die Skalierung der Frequenzachse erfolgt in 1000
Hz-Schritten (in Ausnahmefällen in 500 Hz-Schritten). Bei
Betrachtung der Vokale genügt in der Regel der Frequenzbereich
von 0-4000 Hz, da die relevanten Vokalformanten F1 bis F3 bei
erwachsenen Sprechern meist darunter liegen. Hierbei wird eine
Skalierung in 500-Hz-Schritten vorgenommen. Um Irrtümer zu
vermeiden, ist die Frequenzachse jedes der hier verwendeten
Sonagramme eindeutig beschriftet.
Weitere Beispiele dafür sind der Frikativ /h/, der seine
spektralen Eigenschaften weitgehend aus den angrenzenden Vokalen
bezieht oder aber die variable Artikulationsstelle des velaren
Plosivs /k, g/ in Abhängigkeit vom Vokalkontext.